Comparación de algoritmos
Contenido
6.2. Comparación de algoritmos¶
El rendimiento de los algoritmos utilizados anteriormente no puede ser comparado directamente por las distribuciones de las variables de acuerdo a la clasificación realizada por los modelos. Como se evidencia en la sección anterior, un algoritmo puede parecer ajustar muy bien a los datos en una variable, pero no en otra. Por ello, utilizamos las métricas explicadas en la Sección 4.4 para comparar directamente el rendimiento de los algoritmos. En esta sección se compararán los algoritmos utilizados en la sección anterior, agregando UCluster y GAN-AE.
Los resultados presentados en esta sección se obtuvieron utilizando el pipeline de benchtools, descrito en la Sección 4.5.3.
6.2.1. Conjunto R&D¶
En la sección anterior, se mostraron las distribuciones de algunas variables de acuerdo a la clasificación realizada por cada modelo. Esto se hizo con el objetivo de tener una idea general de cómo están clasificando los algoritmos y para poder asociar esta clasificación a las métricas que se mostrarán a continuación.
La clasificación realizada por los algoritmos de las LHCO 2020 para el conjunto R&D no se lleva a cabo utilizando el mismo subconjunto de datos en todos los modelos, contrario a los empleados en este trabajo, que se entrenan y clasifican utilizando los mismos subconjuntos de entrenamiento y prueba. Estos subconjuntos varían para los algoritmos de las olimpiadas de acuerdo al código publicado por los participantes. Sin embargo, el subconjunto usado para calcular las métricas a continuación no fue utilizado para entrenamiento en ninguno de los modelos.
6.2.1.1. Métricas numéricas¶
En la Figura 6.9 se presenta una comparación visual de las métricas numéricas: exactitud balanceada, precisión, recuperación y puntaje f1, definidas en la Tabla 4.3.
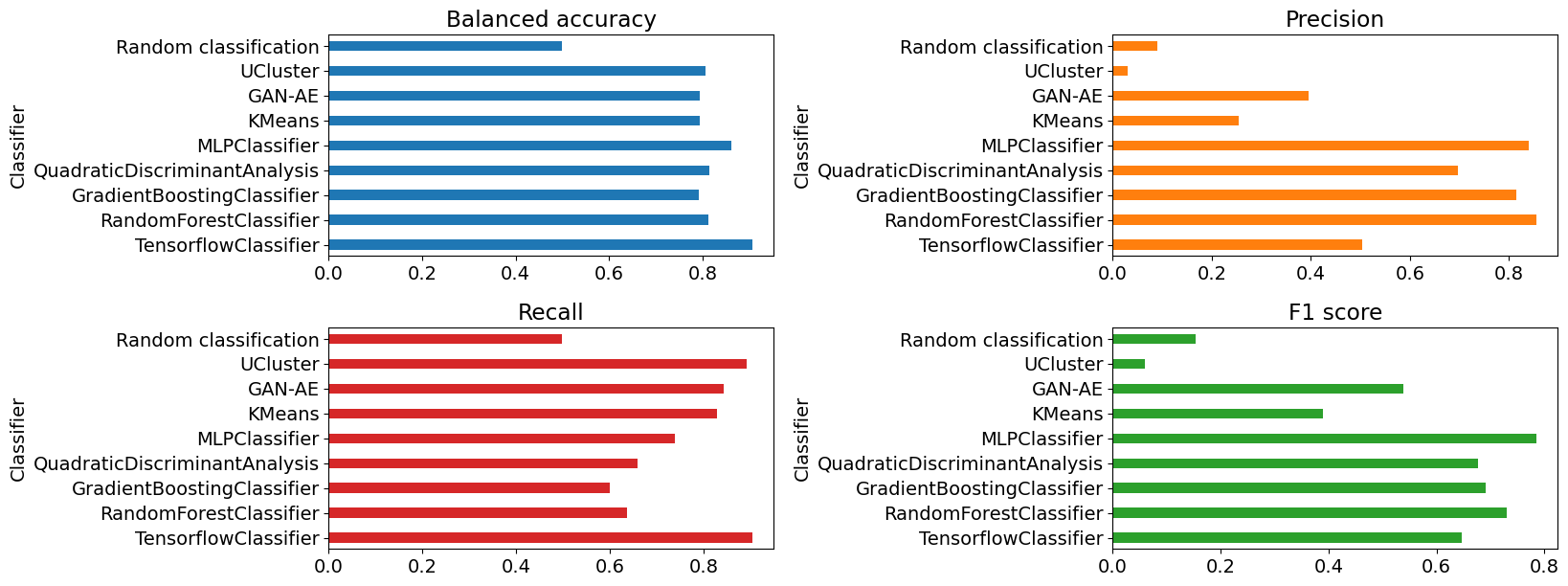
Figura 6.9 Diagramas de barras de las métricas numéricas obtenidas utilizando el pipeline de benchtools para el conjunto R&D. De izquierda a derecha, en la fila superior: exactitud balanceada y precisión. En la fila inferior: recuperación y puntaje f1.¶
Todos los modelos obtuvieron un puntaje de exactitud balanceada mayor a 70%, lo que se considera alto. Sin embargo, la precisión y la recuperación varía entre los clasificadores.
Los modelos supervisados QDA, GB y RFC obtuvieron altos puntajes de precisión, pero bajos puntajes de recuperación. Esto significa que los algoritmos clasifican pocos eventos como señal, pero estas clasificaciones son mayormente correctas. En contraste, el modelo MLP obtuvo un alto puntaje de precisión y recuperación. A su vez, el modelo de TensorFlow obtuvo un menor puntaje de precisión, pero el mayor puntaje de recuperación. Es decir, clasifica más eventos como señal, clasificando eventos de fondo incorrectamente, pero logra clasificar la mayoría de los eventos de señal con la etiqueta correcta.
Los modelos no supervisados KMeans, UCluster y GAN-AE son los modelos con menor precisión, pero mayor recuperación. Es decir, están etiquetando una mayor cantidad de eventos de fondo incorrectamente como señal, pero entre los eventos etiquetados como señal, se encuentra la mayor parte de los eventos de la señal simulada utilizada.
La media armónica de estas dos métricas se observa en el gráfico del puntaje f1, donde, en general, los modelos supervisados obtuvieron puntajes más altos que los modelos no supervisados.
El mayor puntaje f1 fue alcanzado por MLP. Por otra parte, el mayor puntaje de precisión lo logró RFC y el mayor puntaje de recuperación lo consiguió el modelo de TensorFlow, que también obtuvo el mayor puntaje de exactitud balanceada. Los menores puntajes fueron obtenidos por UCluster, con la menor precisión y menor puntaje f1, y por GBC, con el menor puntaje de exactitud balanceada y recuperación.
Los modelos supervisados obtienen una mejor clasificación porque poseen más información en el momento del aprendizaje, puesto que utilizan las etiquetas de los eventos, mientras que los modelos no supervisados requieren estructura en los datos de entrenamiento. Si el conjunto de datos original no posee esta estructura naturalmente, se debería lograr mediante el preprocesamiento. Sin embargo, el preprocesamiento de los tres modelos no supervisados no logró una estructura suficientemente significativa como para obtener una mejor clasificación que las de los modelos supervisados.
Se consideró una clasificación aleatoria en la que un modelo predice que el 50% de los eventos son señal y el 50% son fondo, aleatoriamente. La clasificación aleatoria obtuvo los menores puntajes excepto en la precisión y el puntaje f1, donde UCluster obtuvo menor puntaje. En general, los modelos clasifican mejor que un clasificador aleatorio, salvo UCluster.
Un resumen de los valores numéricos obtenidos se encuentran en la Tabla 6.2.
Clasificador |
Exactitud balanceada |
Precisión |
Recuperación |
Puntaje f1 |
|---|---|---|---|---|
Random classification |
0.50 |
0.09 |
0.15 |
0.50 |
TensorflowClassifier |
0.91 |
0.50 |
0.90 |
0.65 |
RandomForestClassifier |
0.81 |
0.86 |
0.64 |
0.73 |
GradientBoostingClassifier |
0.79 |
0.81 |
0.60 |
0.69 |
QuadraticDiscriminantAnalysis |
0.81 |
0.70 |
0.66 |
0.68 |
MLPClassifier |
0.86 |
0.84 |
0.74 |
0.79 |
KMeans |
0.79 |
0.26 |
0.83 |
0.39 |
GAN-AE |
0.80 |
0.40 |
0.84 |
0.54 |
UCluster |
0.81 |
0.03 |
0.89 |
0.06 |
6.2.1.2. Métricas bidimensionales¶
En la sección anterior se consideró la clasificación después de cortar en un umbral específico para cada clasificador. A continuación, observaremos las métricas bidimensionales, que proporcionan información más general del rendimiento de los algoritmos, porque se obtiene el rendimiento para múltiples umbrales.
Las métricas bidimensionales obtenidas con el pipeline de benchtools son la eficiencia de señal vs. rechazo de fondo, la ROC inversa, la curva precisión recuperación y la mejora de la significancia, definidas en la Sección 4.4.2.
De acuerdo a todas las métricas bidimensionales, el modelo MLP es el que tiene un mejor rendimiento al clasificar el conjunto R&D, con un AUC de 0.98 y una precisión promedio de 0.86, de acuerdo a la Figura 6.10.
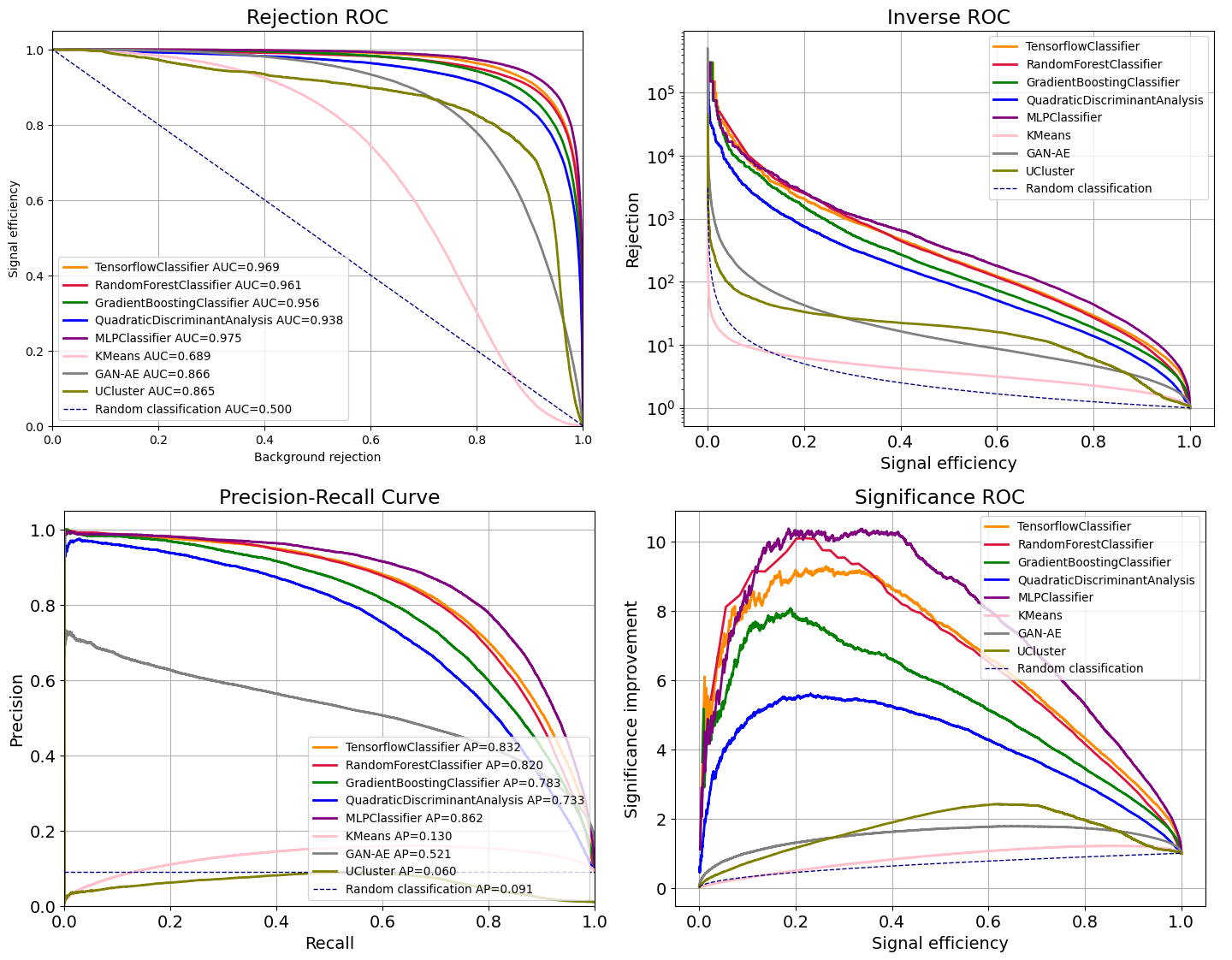
Figura 6.10 Métricas bidimensionales para la clasificación del conjunto R&D. De izquierda derecha, en la fila superior: eficiencia de señal vs. rechazo de fondo, ROC inversa, y en la fila inferior: precisión-recuperación y mejora significativa.¶
Del gráfico de eficiencia de señal vs. rechazo de fondo y del gráfico de precisión-recuperación, observamos que el clasificador de TensorFlow se encuentra en segundo lugar con un AUC de 0.97 y una precisión media de 0.83. Seguido de estos modelos, se encuentran RFC, GBC y QDA en todas las métricas.
Los modelos no supervisados obtuvieron menores puntajes que los supervisados. De acuerdo al AUC, GAN-AE obtiene resultados similares UCluster, con 0.87. GAN-AE también obtiene un mejor resultado según la curva de precisión-recuperación, con una precisión media de 0.52, mientras que la clasificación de UCluster da una precisión media de 0.06, cercana al clasificador aleatorio.
Por último, KMeans obtuvo el menor AUC y la curva de este modelo se encuentra por debajo de todos los demás modelos en todos los gráficos, excepto el de precisión-recuperación. De acuerdo a este gráfico, KMeans obtiene un mejor resultado que UCluster, con una precisión promedio de 0.13 y 0.06, respectivamente.
Las razones por las que algunos modelos tienen mejor rendimiento que otros al clasificar este conjunto de datos, se discutirán en la Sección 7.
En este trabajo, es de interés conocer qué tan bien funcionan los algoritmos al clasificar señal y fondo en conjuntos de datos desconocidos para los modelos, con variaciones en las distribuciones de masa, como el conjunto BB1.
6.2.2. Conjunto BB1¶
A diferencia de las predicciones realizadas con el conjunto R&D, las predicciones para el conjunto BB1 se hacen sobre todos los eventos, utilizando los modelos entrenados previamente con el 70% del conjunto R&D. Las métricas obtenidas en este apartado proveen una medida más cercana al verdadero rendimiento de los algoritmos para detectar anomalías.
6.2.2.1. Métricas numéricas¶
En la Figura 6.11 vemos que las métricas varían con respecto a lo obtenido para el conjunto R&D.
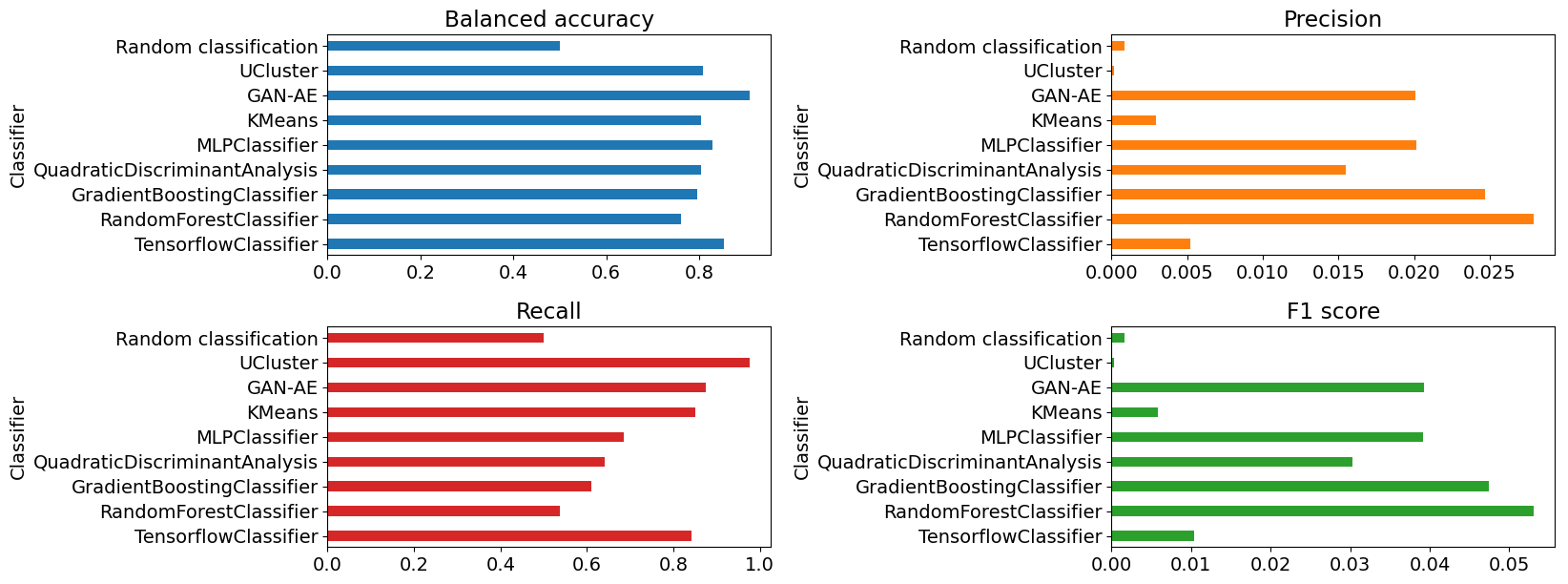
Figura 6.11 Diagramas de barras de las métricas numéricas obtenidas utilizando el pipeline de benchtools para el conjunto BB1. De izquierda a derecha, en la fila superior: exactitud balanceada y precisión. En la fila inferior: recuperación y puntaje f1.¶
La exactitud balanceada sigue siendo alta para todos los algoritmos pero la precisión disminuyó notablemente para todos los modelos. En este conjunto, la mayor precisión fue lograda por RFC con 0.03 de precisión, contrario a la precisión obtenida para el conjunto R&D, de 0.86. Esto implica que los algoritmos clasifican más eventos de fondo incorrectamente, o menos eventos de señal correctamente, en el conjunto BB1.
La recuperación aumentó para los modelos GBC, GAN-AE y UCluster. Para UCluster, GAN-AE, KMeans y el clasificador de TensorFlow, la recuperación se mantuvo cercana o sobre el 0.80. La baja precisión y alta recuperación indica que los modelos están clasificando una gran cantidad de eventos de fondo como señal. Sin embargo, en estos eventos clasificados como señal, logran clasificar la señal esperada.
Debido a la baja precisión, el puntaje f1 se vio afectado y disminuyó notablemente para todos los clasificadores. El clasificador con mayor puntaje es RFC, con un puntaje f1 de 0.05, mientras que en el conjunto R&D obtuvo 0.73.
Nuevamente, el clasificador aleatorio obtuvo métricas más bajas que todos los modelos, excepto en la precisión y el puntaje f1, donde UCluster obtuvo las métricas más bajas.
Clasificador |
Exactitud balanceada |
Precisión |
Recuperación |
Puntaje f1 |
|---|---|---|---|---|
Random classification |
0.50 |
0.00 |
0.50 |
0.00 |
TensorflowClassifier |
0.84 |
0.00 |
0.82 |
0.01 |
RandomForestClassifier |
0.70 |
0.04 |
0.41 |
0.07 |
GradientBoostingClassifier |
0.72 |
0.04 |
0.44 |
0.07 |
QuadraticDiscriminantAnalysis |
0.69 |
0.03 |
0.39 |
0.05 |
MLPClassifier |
0.81 |
0.00 |
0.91 |
0.01 |
KMeans |
0.81 |
0.00 |
0.79 |
0.01 |
GAN-AE |
0.91 |
0.02 |
0.88 |
0.04 |
UCluster |
0.81 |
0.00 |
0.98 |
0.00 |
6.2.2.2. Métricas bidimensionales¶
Las métricas bidimensionales también varían con respecto a las obtenidas utilizando el conjunto R&D. Los resultados se encuentran en la Figura 6.12.
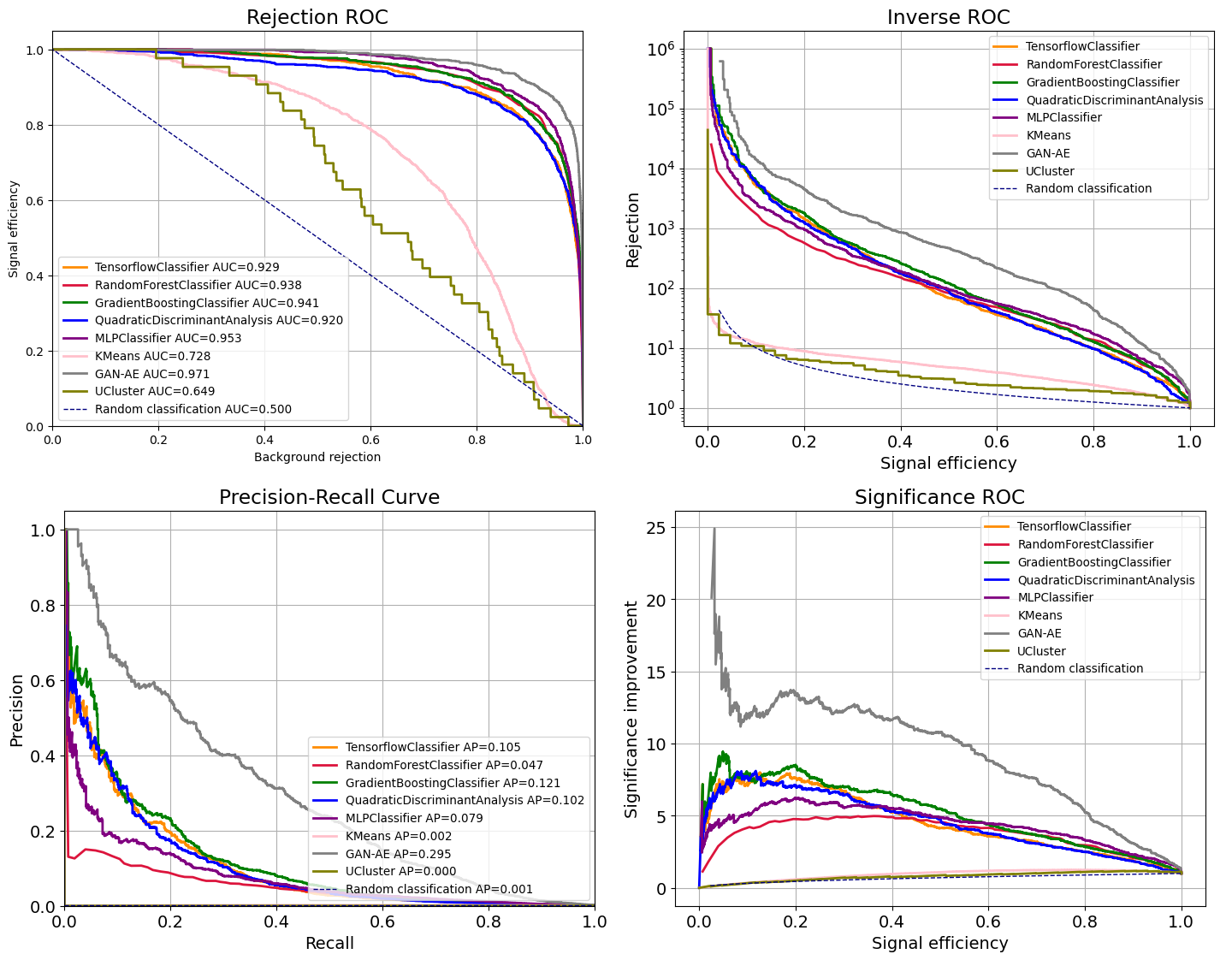
Figura 6.12 Métricas bidimensionales obtenidas para el conjunto BB1. De izquierda derecha, en la fila superior: eficiencia de señal vs. rechazo de fondo, ROC inversa, y en la fila inferior: precisión-recuperación y mejora significativa.¶
De acuerdo al AUC, el rendimiento mejoró en este conjunto para KMeans y GAN-AE, y disminuyó para los demás modelos. Sin embargo, de acuerdo a la precisión promedio, todos los modelos tuvieron menor rendimiento al clasificar este conjunto.
En todos los gráficos, es evidente que GAN-AE tiene un mejor rendimiento en este conjunto de datos que los demás modelos. Que un modelo no supervisado haya logrado una mejor clasificación en este conjunto indica que tiene una mejor capacidad de generalización. Esta capacidad de generalización no se observó en KMeans y UCluster, siendo estos los clasificadores con menor rendimiento al clasificar el conjunto de datos BB1.
De acuerdo al gráfico de eficiencia de señal vs. rechazo de fondo, el algoritmo con mejores resultados después de GAN-AE es MLP, con un AUC de 0.953. Seguido a estos modelos, no es evidente cuál da un mejor resultado entre GBC y RFC y entre QDA y el clasificador de TensorFlow. De acuerdo al AUC, a MLP le sigue GBC, RFC, el clasificador de TensorFlow, QDA y RFC. Los algoritmos no supervisados KMeans y UCluster son los que tuvieron menor rendimiento, donde UCluster obtuvo el rendimiento más bajo.
De la métrica de precisión-recuperación también se obtuvo un mejor resultado para GAN-AE en comparación a los demás modelos, seguido de GBC, el clasificador de TensorFlow y QDA, que obtuvieron una mayor precisión promedio que el modelo MLP. A este le sigue RFC y por último los modelos no supervisados KMeans y UCluster, donde UCluster obtuvo la menor precisión promedio, de 0.000. Este mismo orden de rendimiento de los modelos se obtiene en el gráfico de mejora significativa.
En general, las curvas de UCluster y KMeans se mantienen cercanas a las de un clasificador aleatorio, excepto en el gráfico de eficiencia de señal vs. rechazo de fondo, donde se obtienen curvas que indican una clasificación mejor a la del clasificador aleatorio.
En el siguiente capítulo, se discutirán las razones por las que los algoritmos disminuyen su rendimiento en este conjunto de datos y por qué GAN-AE tiene mejor rendimiento que los demás modelos.