Paquete benchtools
Contenido
4.5. Paquete benchtools¶
Como se mencionó en la Sección 4.1, los conjuntos de datos de las LHCO 2020 incluyen todos los hadrones producto de la colisión entre protones. A partir de estos datos, nos interesa reconstruir los jets de cada evento para analizar variables cinemáticas y de subestructura (definidas en la Sección 2.5.2), entrenar los algoritmos explicados en la Sección 4.2 y compararlos utilizando las métricas explicadas en la Sección 4.4. Sin embargo, para trabajar con 1,000,000 de colisiones, donde hay posibilidad tener los datos de 700 hadrones por evento, con 3 medidas por hadrón (es decir, 2,100,000,000 de variables), es necesario desarrollar algunas herramientas para facilitar su manejo.
En esta sección, se describirá de manera general el paquete de software basado en Python benchtools, desarrollado para este trabajo. El paquete incluye herramientas para el manejo de datos, agrupamiento jets, comparación de algoritmos de clasificación binaria, entre otros. Información más detallada sobre el paquete y cómo utilizarlo se puede encontrar en el repositorio, donde se publicó de manera abierta el código utilizado, siguiendo los lineamientos planteados en la Sección 3.3.
4.5.1. Funciones¶
El paquete se puede dividir en dos partes principales: las funciones y el pipeline. Una función es un bloque de código que resuelve un problema concreto y es lo que utilizamos para armar el pipeline. Recibe cero o más argumentos de entrada y devuelve un argumento de salida o realiza una tarea. En el caso de benchtools, se agruparon funciones en cinco módulos diferentes de acuerdo a su utilidad.
Las funciones se dividen en los siguientes módulos:
datatools: funciones para manejar los datos. Por ejemplo, leer datos iterativamente, unir tablas de datos, entre otras.
substructure: funciones para calcular variables cinemática y de subestructura de los jets.
clustering: funciones para preprocesar los datos. Por ejemplo, agrupar los jets, calcular las variables de un jet, entre otras.
plotools: funciones para graficar datos. La característica principal es que se grafican los datos separando la señal del fondo.
metrictools: funciones para calcular métricas de rendimiento de algoritmos de clasificación binaria.
Las funciones en datatools y substructure son utilizadas principalmente en otras funciones y su contenido no se discutirá en este trabajo. Las funciones en plotools se utilizarán más adelante y se observará su funcionamiento, por lo que omitiremos su explicación.
En metrictools hay múltiples funciones que calculan y grafican las métricas de rendimiento. Para calcular las métricas numéricas, en general se va a utilizar compare_metrics, que calcula la exactitud balanceada, la precisión, el puntaje f1 y la recuperación para múltiples clasificadores. Las métricas bidimensionales incluidas en el paquete son la curva ROC y sus variaciones (ROC inversa y eficiencia de señal vs. rechazo de fondo), la curva PR y la curva de mejora significativa. Por último, en este archivo se encuentra una clase clasificador, que se utiliza para guardar los resultados de la clasificación en un objeto que contenga el nombre del clasificador, el puntaje de cada evento asociado a la probabilidad de ser señal, la etiqueta binaria predicha para cada evento y la etiqueta real.
En clustering se encuentra la función que realiza el preprocesamiento de los datos, build_features, y las funciones que la confoman.
4.5.2. Preprocesamiento de datos¶
El preprocesamiento de datos se realiza para obtener variables físicas a partir de los datos de los jets. Estas variables son utilizadas por los modelos para entrenamiento y clasificación. Los pasos para preprocesar son los siguientes:
Algorithm 4.2 (Preprocesamiento de benchtools)
Input: Datos de todos los hadrones de los eventos.
Output: Variables físicas para cada evento.
Importar una fracción de los eventos. Para cada fracción de eventos:
Agrupar los jets de cada evento utilizando anti-kt con \(R=1\).
Seleccionar los jets que tengan \(pT>20GeV\)
Calcular \(pT\), \(m_j\), \(\eta\), \(\phi\), \(E\), \(\tau_{21}\) y el número de hadrones constituyentes, para los dos jets más energéticos. \(\Delta R\), \(m_{jj}\) utilizando los dos jets principales y el número de hadrones del evento.
Guardar las variables calculadas en un marco de datos.
Este proceso se hace paralelamente para fracciones de datos, debido a que importar todos los eventos requiere gran cantidad de memoria. Luego, se unen los archivos para tener un solo conjunto de datos preprocesados.
La descripción de cada variable calculada se encuentra Tabla 4.4.
Variable |
Descripción |
|---|---|
\(pT_{ji}\) |
Momento transversal del jet i |
\(m_{ji}\) |
Masa invariante del jet i |
\(\eta_{ji}\) |
Pseudorapidez del jet i(ec.(2.1)) |
\(\phi_{ji}\) |
Ángulo azimutal en el plano transverso del jet i |
\(E_{ji}\) |
Energía del jet i |
\(\tau_{21,ji}\) |
Subjetiness del jet i (ec.(2.6)) |
nro. hadrones \(ji\) |
Número de hadrones constituyentes del jet i |
\(\Delta R\) |
Distancia angular entre los dos jets principales (ec.(2.2)) |
\(m_{jj}\) |
Masa invariante de los dos jets principales |
nro. hadrones |
Número de hadrones del evento |
La masa invariante de los dos jets \(m_{jj}\) está definida como: $\( m_{jj}= \sqrt{(E_{j1}+E_{j2})-|p_{j1}+p_{j2}|^2}. \)$ (masa invariante)
4.5.3. Pipeline¶
En programación, un pipeline consiste en una serie de pasos en los que la salida de un paso es la entrada del siguiente. Uno de los objetivos de este trabajo fue la creación de un pipeline que acepta como entrada los datos proporcionados en las olimpiadas y que tiene como salida la comparación del resultado de varios algoritmos. El pipeline de benchtools preprocesa los datos, entrena los modelos explicados en la Sección 4.2, realiza la clasificación y compara los resultados con clasificaciones realizadas externamente, utilizando las métricas de rendimiento descritas anteriormente. Los pasos se describen a continuación:
Algorithm 4.3 (Pipeline de benchtools)
Input: Datos de los eventos y lista de los clasificadores externos a comparar, salvados como un objeto classifier.
Output: Imagenes de los gráficos de las métricas y una tabla con las métricas númericas, así como gráficos de barra de cada variable.
Preprocesar los datos de los eventos.
Transformar los datos para que estén confinados en un rango de valores según el clasificador a utilizar, entrenar los modelos y salvarlos.
Evaluar los puntajes y predicciones de cada clasificador.
Importar las clasificaciones externas.
Comparar los algoritmos utilizando las métricas en metrictools.
Para entrenar los modelos, se utilizan las variables descritas en la Tabla 4.4, a excepción de \(m_{jj}\) y \(m_{ji}\), para evitar que los modelos aprendan la masa de las partículas, y obtener una clasificación lo más libre de modelo posible.
El pipeline posee opciones para realizar algunos o todos los pasos. Un diagrama de este proceso se muestra la Figura 4.14.
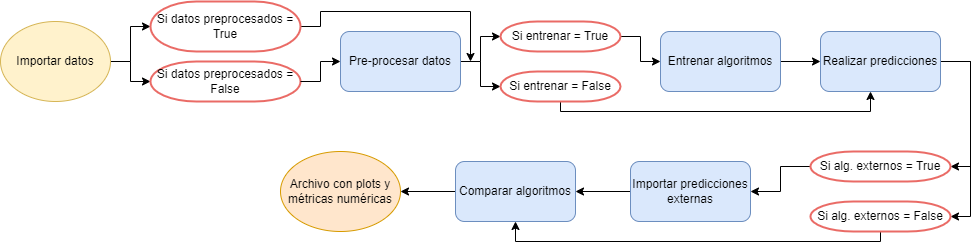
Figura 4.14 Diagrama del pipeline de benchtools.¶
Las opciones para correr el pipeline se encuentran explicadas en el repositorio. Los resultados de su uso se observarán en la Sección 6.2.